Welcome to DRecPy’s documentation!¶
![]()
![]()

Table of Contents¶
Introduction¶
DRecPy is a Python framework that makes building deep learning based recommender systems easier, by making available various tools to develop and test new models.
The main key features DRecPy provides are listed bellow: - Support for in-memory and out-of-memory data sets, by using an intermediary data structure called InteractionDataset.
- Auto Internal to raw id conversion: a mapping from raw to internal identifiers is automatically built, so that datasets containing string ids or non-contiguous numeric ids are supported by all recommenders.
- Support for multi-column data sets, i.e. not being limited to (user, item, rating) triples, but also supporting other columns such as timestamp, session, location, etc.
- Well defined workflow for model building for developing deep learning-based recommenders (while also supporting non-deep learning-based recommenders).
- Support for epoch callbacks using custom functions, whose results are logged and displayed in a plot at the end of model training.
- Early stopping support using custom functions that can make use of previous epoch callback results or model loss values.
- Data set splitting techniques adjusted for the distinct nature of data sets dedicated for recommender systems.
- Sampling techniques for point based and list based models.
- Evaluation processes for predictive models, as well as for learn-to-rank models.
- Automatic progress logging and plot generation for loss values during model training, as well as test scores during model evaluation.
- All methods with stochastic factors receive a seed parameter, in order to allow result reproducibility.
For more information about the framework and its components, please visit the documentation page.
Here’s a brief overview of the general call workflow for every recommender:
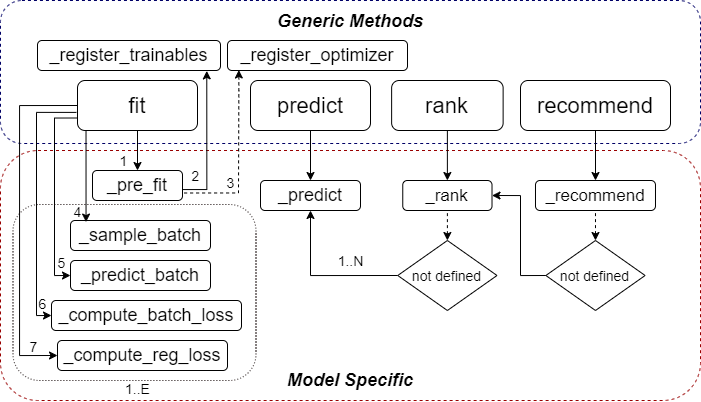
Call Worlflow
Installation¶
With pip:
$ pip install drecpy
If you can’t get the latest version from PyPi:
$ pip install git+https://github.com/fabioiuri/DRecPy
Or directly by cloning the Git repo:
$ git clone https://github.com/fabioiuri/DRecPy
$ cd DRecPy
$ python setup.py install
Getting Started¶
Here’s an example script using one of the implemented recommenders (CDAE), to train, with a validation set, and evaluate its ranking performance on the MovieLens 100k data set.
from DRecPy.Recommender import CDAE
from DRecPy.Recommender.EarlyStopping import MaxValidationValueRule
from DRecPy.Dataset import get_train_dataset
from DRecPy.Dataset import get_test_dataset
from DRecPy.Evaluation.Processes import ranking_evaluation
from DRecPy.Evaluation.Splits import leave_k_out
from DRecPy.Evaluation.Metrics import NDCG
from DRecPy.Evaluation.Metrics import HitRatio
from DRecPy.Evaluation.Metrics import Precision
import time
ds_train = get_train_dataset('ml-100k')
ds_test = get_test_dataset('ml-100k')
ds_train, ds_val = leave_k_out(ds_train, k=1, min_user_interactions=10, seed=0)
def epoch_callback_fn(model):
return {'val_' + metric: v for metric, v in
ranking_evaluation(model, ds_val, n_pos_interactions=1, n_neg_interactions=100,
generate_negative_pairs=True, k=10, verbose=False, seed=10,
metrics=[HitRatio(), NDCG()]).items()}
start_train = time.time()
cdae = CDAE(hidden_factors=50, corruption_level=0.2, loss='bce', seed=10)
cdae.fit(ds_train, learning_rate=0.001, reg_rate=0.001, epochs=100, batch_size=64, neg_ratio=5,
epoch_callback_fn=epoch_callback_fn, epoch_callback_freq=10,
early_stopping_rule=MaxValidationValueRule('val_HitRatio'), early_stopping_freq=10)
print("Training took", time.time() - start_train)
print(ranking_evaluation(cdae, ds_test, k=[1, 5, 10], novelty=True, n_pos_interactions=1,
n_neg_interactions=100, generate_negative_pairs=True, seed=10,
metrics=[HitRatio(), NDCG(), Precision()], max_concurrent_threads=4, verbose=True))
Output:
Creating user split tasks: 100%|██████████| 943/943 [00:00<00:00, 4704.11it/s]
Splitting dataset: 100%|██████████| 943/943 [00:03<00:00, 296.04it/s]
[2020-09-02 00:13:37,764] (INFO) CDAE_CLOGGER: Max. interaction value: 5
[2020-09-02 00:13:37,764] (INFO) CDAE_CLOGGER: Min. interaction value: 0
[2020-09-02 00:13:37,764] (INFO) CDAE_CLOGGER: Interaction threshold value: 0.001
[2020-09-02 00:13:37,764] (INFO) CDAE_CLOGGER: Number of unique users: 943
[2020-09-02 00:13:37,765] (INFO) CDAE_CLOGGER: Number of unique items: 1680
[2020-09-02 00:13:37,765] (INFO) CDAE_CLOGGER: Number of training points: 89627
[2020-09-02 00:13:37,765] (INFO) CDAE_CLOGGER: Sparsity level: approx. 94.3426%
[2020-09-02 00:13:37,765] (INFO) CDAE_CLOGGER: Creating auxiliary structures...
[2020-09-02 00:13:37,833] (INFO) CDAE_CLOGGER: Number of registered trainable variables: 5
Fitting model... Epoch 100 Loss: 0.1882 | val_HitRatio@10: 0.5493 | val_NDCG@10: 0.3137 | MaxValidationValueRule best epoch: 80: 100%|██████████| 100/100 [15:05<00:00, 29.77s/it]
[2020-09-02 00:30:02,831] (INFO) CDAE_CLOGGER: Reverting network weights to epoch 80 due to the evaluation of the early stopping rule MaxValidationValueRule.
[2020-09-02 00:30:02,833] (INFO) CDAE_CLOGGER: Network weights reverted from epoch 100 to epoch 80.
[2020-09-02 00:30:02,979] (INFO) CDAE_CLOGGER: Model fitted.
Starting user evaluation tasks: 100%|██████████| 943/943 [00:00<00:00, 2454.84it/s]
Evaluating model ranking performance: 99%|█████████▊| 929/943 [02:16<00:02, 4.81it/s]
{'HitRatio@1': 0.1198, 'HitRatio@5': 0.3945, 'HitRatio@10': 0.5536, 'NDCG@1': 0.1198,
'NDCG@5': 0.2588, 'NDCG@10': 0.3103, 'Precision@1': 0.1198, 'Precision@5': 0.0789, 'Precision@10': 0.0554}
Generated Plots:
- Training
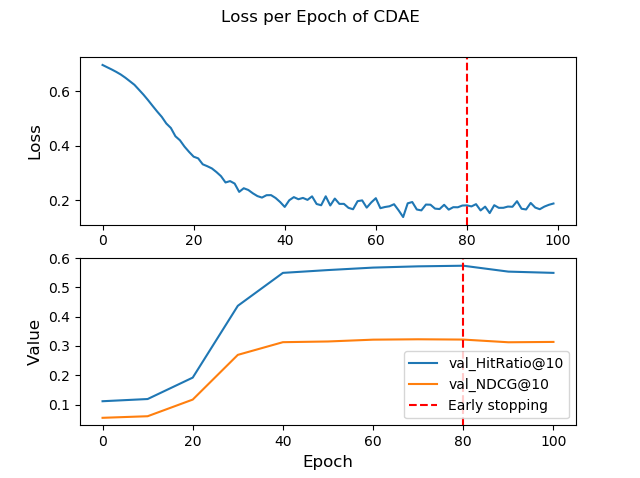
CDAE Training Performance
- Evaluation
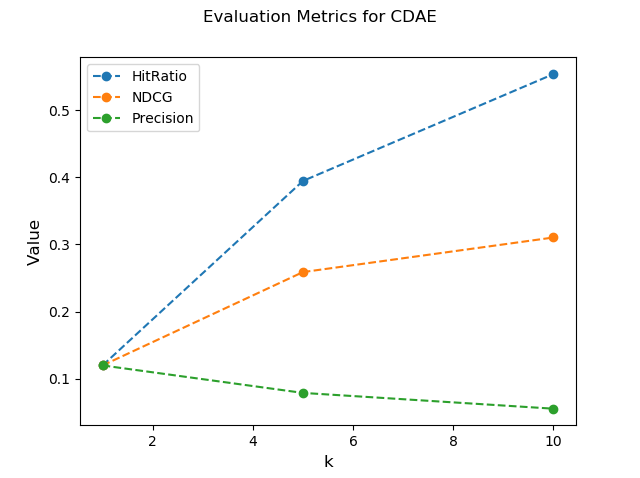
CDAE Evaluation Performance
More quick and easy examples are available here.
Implemented Models¶
| Recommender Type | Name |
|---|---|
| Learn-to-rank | CDAE (Collaborative Denoising Auto-Encoder) |
| Learn-to-rank | DMF (Deep Matrix Factorization) |
Implemented Baselines (non deep learning based)¶
| Recommender Type | Name |
|---|---|
| Predictive | User/Item KNN |
Benchmarks¶
TODO
License¶
Check LICENCE.md.
Contributors¶
This work was conducted under the supervision of Prof. Francisco M. Couto, and during the initial development phase the project was financially supported by a FCT research scholarship UID/CEC/00408/2019, under the research institution LASIGE, from the Faculty of Sciences, University of Lisbon.
Public contribution is welcomed, and if you wish to contribute just open a PR or contect me fabioiuri@live.com.
Development Status¶
Project in alpha stage.
Planned work:
- Wrap up missing documentation
- Implement more models
- Refine and clean unit tests
If you have any bugs to report or update suggestions, you can use DRecPy’s github issues page or email me directly to fabioiuri@live.com.